Moon, Gyeongsik, Ju Yong Chang, and Kyoung Mu Lee. "Camera distance-aware top-down approach for 3d multi-person pose estimation from a single rgb image." Proceedings of the IEEE International Conference on Computer Vision. 2019.
Abstract
3D human pose estimation의 최근까지 연구는 한 사람일 때만 추정하는 것으로 제한되어왔다. 이 논문에서는 3D multi person pose estimation으로 fully learning 기반, carmera distance aware top-down 방법을 제안한다. 이 시스템은 크게 human detection, absolute 3D human root localization, root relative 3D single persion pose estimation 3개의 모듈들로 구성된다. 실측정보없이 single person pose estimation에서 좋은 성능을 보이며, multi persion pose estimation은 기존 최신 기술보다 큰 성능 향상을 보인다.

Introduction
3D human pose estimation은 인간의 행동 이해와 인간과 컴퓨터의 상호작용을 위한 필수적인 기술이다. 최근 연구는 deep CNN과 많은 양의 데이터셋을 통해 성능이 향상되고 있다. 지금까지의 3D human pose estimation은 사람 1명을 bounding box를 통해 자른 다음에 이를 모듈에 넣어 인식하는 방식이었다. 인체 각 키포인트의 절대 좌표를 얻기 어렵기 때문에 많은 연구들은 root(골반)라 불리는 절대 좌표에 상대 위치를 추가하여 키포인트를 추정한다.
3D multi person pose estimation은 2D bounding box뿐만 아니라 카메라와 사람의 절대 거리를 추정해야하기 때문에 어려운 문제이다. 본 연구의 3D multi persion pose estimation은 완전 학습 기반, 카메라 거리 인식 top-down 접근법을 제안하는 최초의 연구이다. 제안된 시스템의 파이프라인은 3개의 모듈로 구성된다.
˙ DetectNet : 사람의 bounding box를 추정
˙ RootNet : 카메라를 중심으로 root의 좌표를 추정
˙ PoseNet : root를 기반으로 상대적인 포즈를 추정
아래는 위에서 설명한 파이프라인 구조를 보여주는 그림이다.
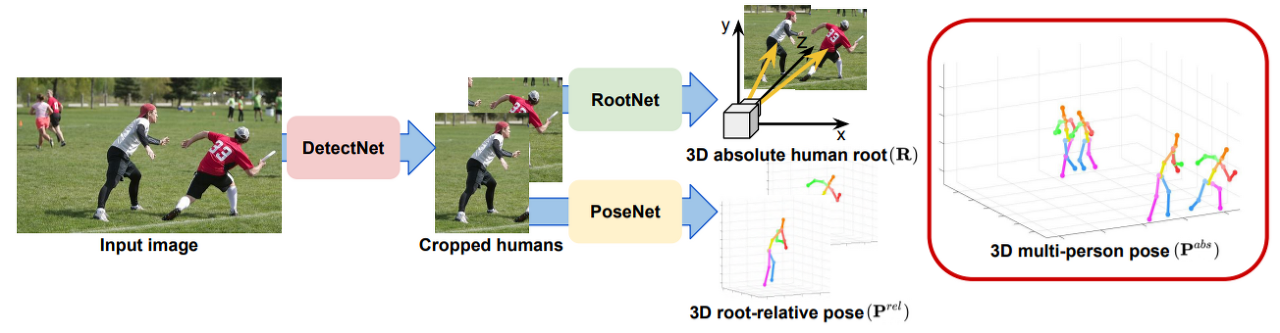
이 시스템은 이전의 3D multi person pose estimation 성능을 크게 능가한다. 또한, 실측정보(bounding box, root의 위치)가 없어도 기존 3D single person pose estimation과 비슷한 성능을 보인다. 추가로, 기존 estimation방법과 쉽게 연결할 수 있어 프레임워크를 유연하고 일반화하여 적용할 수 있다는 것이 장점이다.
Related Works
2D multi-person pose estimation
크게 Top-down approach, Bottom-up approach가 있다. Top-down approach는 human detector를 통해 bounding box를 추정하고 이를 잘라 포즈를 분석하는 방식이다. Bottom-up approach는 모든 인체 키포인트를 localize한 뒤에 사람별로 그룹화하는 방식이다.
3D single-person pose estimation
Single stage approach, Two stage approach로 나눌 수 있다. Single stage approach는 이미지를 바로 3D 인체 키포인트에 직접 매핑시키는 방식이고, Two stage approach는 2D 공간상에 키포인트를 위치 시킨뒤, 3D 공간에 옮기는 방식이다. 일반적으로 Two stage approach가 좋은 성능을 보이고 있다.
3D multi-person pose estimation
단일 RGB이미지로부터 3D multi person pose estimation에 대한 연구는 거의 없었다. LCR-Net이라는 Top-down approach 방식은 localization, classification, regression으로 구성된다. Localization에서 이미지로부터 사람을 검출하고 Classification에서 탐지한 사람을 몇개의 기본 포즈로 분류한다. Regression에서는 기본 포즈를 세분화한다.
3D human root localization in 3D multi-person pose estimation
Rogez et al.은 2D 포즈와 3D 포즈를 동시에 추정하는 방법을 사용하였다. 추정된 2D 포즈와 투영된 3D 포즈의 거리를 최소화함으로써 root 위치를 획득하였다. 하지만 많은 3D single-person pose estimation은 카메라 중심의 루트 기준 상대좌표를 출력하지 않기 때문에 최소화 전략을 사용하기 어렵다. 또한, 이미지 특징이 고려되지 않아 상황정보가 이용되지 않는다. 예를 들어, 가까운 어린이와 멀리 있는 어른을 구분할 수 없다.
Overview of the proposed model
이 시스템의 주 목적은 이미지로부터 사람의 키포인트 $\{ P_j^{abs} \}_{j=1}^{J}$ 위치들을 복구하는 것이다. DetectNet은 사람을 탐지하고 bounding box를 추정하여 이미지를 자른다. RootNet은 각 자른 이미지의 root의 위치 $R= (x_R, y_R, Z_R)$를 추정한다. $Z_R$은 절대 깊이 값이다. PoseNet은 같은 자른 이미지를 받아서 root 상대위치 $P_j^{rel} = (x_j, y_j, Z_j^{rel})$를 추정한다. 여기서 $Z_j^{rel}$은 root 상대 깊이 값이다. $\{ P_j^{abs} \}_{j=1}^{J}$는 RootNet과 PoseNet에서 얻은 $R$과 $P_j^{rel}$를 더함으로써 얻을 수 있다.
DetectNet
DetectNet으로 Mask R-CNN을 사용하며, 세가지 파트로 구성된다. 첫번째, backbone(ResNet 등을 사용)은 입력 이미지로부터 유용한 로컬, 글로벌 특징들을 추출한다. 두번째, region proposal network는 bounding box의 후보들을 제안한다. 세번째, classification head network는 제안된 후보들 중에 좋은 것을 선별한다.
RootNet
RootNet은 사람의 root좌표를 추정한다. 이미지에서 2D 좌표는 쉽게 추정할 수 있지만, 깊이를 추정하는 것은 매우 어렵다. 그 이유는 입력 이미지가 카메라와 사람의 상대적 위치를 제공하지 않기 때문이다. 이 문제를 해결하기 위해 k라는 새로운 깊이 단위를 사용한다.
$k = \sqrt{\alpha_x \alpha_y {A_{real} \over A_{img}}}$
$\alpha_x, \, \alpha_y$는 pixel 단위에서 x축, y축 초점거리를 뜻한다. $A_{real}$은 $mm^2$ 단위를 가지는 실제 공간의 넓이, $A_{img}$은 $pixel^2$단위를 가지는 이미지 공간의 넓이다. k는 실제 넓이와 이미지 넓이의 비율을 이용하여 카메라와 물체까지의 절대 깊이를 근사한다. 이를 증명하기 위해 x축, y축 상에서 카메라와 물체 거리를 다음과 같이 계산할 수 있다. (핀홀 카메라의 비례 원리 이용)
$ d = \alpha_x {l_{x, real} \over l_{x, img}} = \alpha_y {l_{y, real} \over l_{y, img}}$
각 항을 곱하고 제곱근을 취함으로써 k를 도출할 수 있다. 여기서 인간의 경우 $A_{real}$이 일정하고 $2000mm X 2000mm$라 가정한다.
하지만 $A_{real}$이 일정하다 가정함으로써 안좋은 경우가 생긴다. 예를 들어, 사람의 자세에 따라 같은 거리이지만 다른 넓이를 가질 수 있고 사람의 체형에 따라 다른 거리이지만 같은 넓이를 가질 수 있기 때문이다. 이 경우 k가 실제 거리를 반영하지 못한다.
위에서 언급한 문제를 해결하기 위해 k($A_{img}$)를 조정하는 단계를 거친다. RootNet은 이미지 정보를 이용해 k를 얼마나 변경해야하는지를 알아낸다. 예를 들어 사람이 웅크린 자세인 경우 같은 넓이에 비해 가까이 있으므로 k를 작게 변경한다. 어린 아이인경우에도 k를 작게 변경하여 깊이 정보를 조정한다. 아래 그림처럼 RootNet에서 보정 계수 $\gamma$를 계산하고 k에 곱해줌으로써 깊이 정보를 보정한다.

$\gamma$를 둠으로써 다양한 카메라 매개변수($\alpha_x, \alpha_y$)를 training과 testing에 사용될 수 있으며, 이를 camera normalization이라 한다. 그리고 이러한 점은 RootNet을 유연하게 만든다. 예를 들어, training에서 다른 $\alpha_x, \alpha_y$를 가지는 데이터를 학습시킬 수 있고, testing에서 $\alpha_x, \alpha_y$가 주어지지 않더라도 RootNet을 사용할 수 있다.
RootNet은 3가지로 구성된다. 첫번째, Backbone은 ResNet등을 이용하여 특징들을 추출한다. 두번째, 2D image coordinate estimation 부분은 특징들을 이용하여 root의 heat map을 생성하고 2D 좌표를 생성한다. 세번째, Depth estimation 부분은 convolution을 거쳐 스칼라 값 $\gamma$를 출력한다. 최종적으로 절대 깊이 값은 다음과 같이 계산된다.
$ Z_R = {k \over {\sqrt{\gamma}}}$
PoseNet
PoseNet은 root기반 3D 포즈의 상대 위치를 추정한다. 이 네트워크는 이미 많은 선행연구가 진행되어 왔다. 여기서는 Sun et al.의 방법을 사용하고 크게 두개의 부분으로 구성된다. 첫번째, Backbone은 잘려진 이미지에서 유용한 특징들을 추출한다. 그리고 두번째 pose estimation 부분에서는 3D 히트맵을 생성한다.
Implemetation details
COCO dataset에 대해 사전 훈련된 Mask R-CNN모델이 DetectNet에 그대로 사용된다. RootNet, PoseNet의 backbone부분은 ImageNet dataset에 대해 사전훈련된 ResNet-50으로 초기화된다. 나머지 부분은 가우스 분포로 초기화한다. mini batch size는 128로 하고 이미지를 회전, 플립 등 data augumentation을 진행하였다. 초기 학습속도는 $10^{-3}$이고 17 epoch부터는 10배로 감소한다. 4개의 NVIDIA 1080 Ti GPU를 사용하여 2일에 걸쳐 학습하였다.
Experiment
Human 3.6M dataset
이 Dataset은 큰 3D single person pose benchmark로, 15가지 활동을 수행하는 11명의 피사체가 4개의 카메라 시점에서 촬영된 이미지이다. 평가 지표 중 하나는 MPJPE(mean per join posistion error)로 root 위치를 정렬한 다음에 관절 위치 평균으로 평가한다. Root 위치를 평가하기 위해 MRPE(mean root position error)를 정의하는데, 이는 루트와의 유클리드 거리 차이로 평가한다.
MuCo-3DHP and MuPoTs-3D dataset
이 데이터 셋들은 3D multi person pose estimation 데이터 셋들이다. MuCo-3DHP는 존재하는 MPI-INF-3DHP 3D single person pose estimation dataset을 합성하여 만들어졌다. MuPoTs-3D는 3명의 피사체의 20개의 장면들로 구성된다. 평가를 위해 3DPCK(3D percentage of correct keypoints), AUC(area under 3DPCK curve)를 사용하여 3D 포즈를 평가한다. 각 관절이 15cm이내에 있으면 정확한 것으로 판단한다. root 위치 평가를 위해 $AP^{root}$(average precision of 3D human root location)을 정의하고 25cm이내에 있으면 정확한 것으로 판단한다. DetectNet을 평가하기 위해서 $AP^{box}$(average precision of bounding box)를 사용한다.
Disjointed pipline
DetectNet, RootNet, PoseNet을 한꺼번에 학습하는거보다 분리하여 학습시킬 때 오류가 감소한다. 이는 RootNet과 PoseNet이 밀접하게 연관되어있지 않기 때문에 공동으로 학습하면 훈련이 더 어려워져서 정확도가 더 떨어지기 때문이다.
Effect of the DetectNet
아래 표는 DetectNet과 RootNet을 변경해가며 실험한 결과이다. 여러 DetectNet으로 의미있는 성능을 보인다. 특히 Groundtruth를 사용하여도 3D multi person pose estimation 성능이 크게 변하지 않는다. 이는 bounding box estimation accuracy가 3D multi person pose estimation에 큰 영향을 주지 않음을 알 수 있다.

Effect of the RootNet
k를 직접 사용하는 것에 비해 Ours의 $AP^{root}_{25}$, $3DPCK_{abs}$가 높다. 이 결과는 RootNet이 k값을 성공적으로 보정하는 것을 보여준다. 마지막 행에서 RootNet에서 Groundtruth를 사용할 때 $3DPCK_{abs}$이 비약적으로 증가하는 것을 볼 수 있는데, 이는 3D multi person pose estimation의 성능을 높이기 위해서는 사람의 root위치를 정확하게 추정하는 게 중요하다는 것을 알 수 있다.
Effect of PoseNet
Root를 기반인 상대적 위치를 평가하는 $AUC_{rel}$의 경우 DetectNet, RootNet에 관련없이 거의 일정함을 보인다. 이는 $AUC_{rel}$는 PoseNet 성능에 따라 정확도가 결정된다는 결론을 내릴 수 있다.
최종적으로 Human 3.6M dataset에 대해 groundtruth정보가 없어도 비슷한 inference 시간에 비슷한 성능을 보인다. 특히 MuCo-3DHP/MuPoTS-3D dataset, multi person pose estimation에서는 뛰어난 성능을 보인다.
Discussion
제안된 시스템은 기존 multi person pose estimation 성능을 능가할 뿐만 아니라 개선의 여지가 많다. 위에서 언급했듯이 root 위치를 정확하게 추정할 수록 $3DPCK_{abs}$가 크게 향상된다. 이를 개선함으로써 모델을 개선하기 위한 실마리를 찾을 수 있다.
이 프레임워크는 3D multi person pose estimation 뿐만 아니라 여러 응용이 가능하다. 예를들어 3D human mesh model reconstruction에 사용될 수 있다. 단일 RGB 이미지를 입력으로 하는 많은 3D 인식 비전 분야에 적용할 수 있다.
Conclusion
단일 RGB 이미지로부터 3D multi person pose estimation을 위한 새롭고 유연한 프레임워크를 제안했다. DetectNet, RootNet, PoseNet으로 구성되어 이를 기존 프레임워크에 연결할 수 있어 유연하고 사용하기 쉽다. 이 시스템은 단일 인물에서 비슷한 성능을 보이며, 다중 인물에서 기존 보다 큰 성능 향상을 보인다. 이 연구는 3D multi person pose estimation을 해결하기 위해 새로운 방향을 제시하였으며 계속 발전될 가능성이 존재한다.
'Computer Vision > 3D Vision' 카테고리의 다른 글
| Unsupervised Learning of Depth and Ego-Motion from Video (0) | 2020.09.30 |
|---|
